Pernah bertanya-tanya mengapa beberapa halaman website Anda cepat terindeks Google, sementara yang lain seperti tak terlihat?
Apakah crawl budget berarti kita harus membayar Google agar halaman website kita diindeks?
Tapi tunggu dulu, fakta sebenarnya justru lebih menarik dari itu.
Jika Anda serius ingin meningkatkan visibilitas website di Google, memahami dan mengoptimalkan crawl budget adalah langkah krusial.
Yuk, simak panduan lengkap untuk hasil SEO yang lebih baik.
Apa itu Crawl Budget?
Crawl budget adalah jumlah URL di website Anda yang akan dirayapi (di-crawl) oleh mesin pencari seperti Google dalam periode waktu tertentu. Setelah batas tersebut tercapai, Google akan berhenti merayapi dan beralih ke website lain.
Masalahnya?
Ada miliaran website di internet. Sementara itu, mesin pencari punya sumber daya yang terbatas —mereka tidak bisa memeriksa setiap halaman di semua website setiap hari. Jadi, mereka harus pintar-pintar menentukan halaman mana yang layak dirayapi dan kapan waktunya.
Sebelum kita bahas bagaimana mesin pencari memutuskan itu, mari kita pahami dulu kenapa crawl budget sangat krusial untuk performa SEO website Anda.
Catatan
Istilah “SEO” tidak hanya merujuk pada Search Engine Optimization, tetapi juga sering digunakan untuk menyebut seseorang yang ahli di bidang ini, seperti SEO Expert atau SEO Specialist
Mengapa Crawl Budget Penting untuk SEO?
Sebelum halaman Anda bisa muncul dan bersaing di hasil pencarian Google, Google harus terlebih dahulu merayapi (crawl) dan mengindeks halaman tersebut. Dan agar proses ini berjalan dengan baik, tidak boleh ada hambatan teknis.
Jika proses crawling dan indexing terganggu, konten Anda tidak akan muncul di hasil pencarian, yang artinya potensi trafik organik dan pencapaian bisnis Anda bisa terdampak signifikan.
Memang, untuk sebagian besar pemilik website, crawl budget bukan masalah besar. Google cukup efisien dalam merayapi website yang strukturnya sehat dan tidak terlalu besar.
Namun, ada beberapa kondisi khusus di mana crawl budget menjadi faktor penting dalam strategi SEO, seperti:
- Situs Anda Sangat Besar — Jika website Anda memiliki lebih dari 10.000 – 1 jt halaman unik, Google mungkin tidak akan langsung menemukan semua halaman baru atau rutin merayapi ulang seluruh konten lama. Ini bisa membuat sebagian halaman terabaikan dalam indeks.
- Anda Sering Menambahkan Halaman Baru — Jika Anda rutin menambahkan banyak halaman (misalnya situs berita, e-commerce, atau blog aktif), maka alokasi crawl budget sangat memengaruhi seberapa cepat halaman-halaman baru tersebut ditemukan Google.
- Website Anda Memiliki Masalah Teknis — Masalah seperti struktur internal yang buruk, redirect berlebihan, atau error 404 bisa membuat Googlebot kesulitan menjelajahi situs Anda secara efisien. Akibatnya, Google hanya merayapi sebagian kecil dari halaman penting Anda, dan itu merugikan SEO secara keseluruhan.
Dengan kata lain, memahami dan mengoptimalkan crawl budget bukan hanya penting, tapi esensial untuk memastikan setiap halaman berharga di website Anda mendapat kesempatan tampil di halaman pencarian.
Bagaimana Google Menentukan Crawl Budget
Google menggunakan sistem yang disebut crawl budget untuk menentukan berapa banyak halaman dari sebuah website yang akan dirayapi dalam periode tertentu.
Dan jumlah ini tidak acak, melainkan ditentukan oleh dua komponen utama: Crawl Demand dan Crawl Rate Limit.
1. Crawl Demand
Crawl demand adalah tingkat keinginan Google untuk merayapi website Anda berdasarkan seberapa penting dan relevan halaman-halaman Anda di mata algoritma mereka.
Semakin tinggi crawl demand, semakin sering Googlebot akan mengunjungi website Anda untuk mencari pembaruan, konten baru, atau perubahan penting.
Ada tiga faktor utama yang memengaruhi seberapa tinggi crawl demand wesbite Anda:
Perceived Inventory
Google akan berusaha merayapi semua halaman yang diketahui atau ditemukan dari website Anda, kecuali Anda secara eksplisit memberi tahu Google untuk tidak melakukannya.
Artinya, Googlebot bisa saja tetap mencoba mengakses halaman-halaman duplikat, halaman yang sudah Anda hapus, atau halaman yang sebenarnya tidak penting, jika Anda tidak mengatur batasan teknis dengan benar.
Misalnya melalui:
- File
robots.txtuntuk memblokir perayapan - Status kode HTTP 404 (halaman tidak ditemukan) atau 410 (halaman dihapus permanen)
- Tag meta
noindexataucanonicaluntuk mengarahkan prioritas
Jika tidak ditangani, halaman-halaman ini bisa menghabiskan crawl budget secara sia-sia, sehingga halaman penting Anda berisiko tidak dirayapi tepat waktu.
Popularity
Secara umum, Google akan lebih memprioritaskan halaman yang memiliki banyak backlink (tautan dari situs lain) dan halaman yang menarik banyak trafik.
Kedua faktor ini menjadi sinyal bagi algoritma Google bahwa halaman tersebut penting dan layak dirayapi lebih sering.
Namun, penting untuk diingat, jumlah backlink saja tidak cukup. Yang jauh lebih berpengaruh adalah kualitas backlink, yaitu tautan yang relevan dan berasal dari sumber yang memiliki otoritas.
Backlink dari website terpercaya dalam topik yang sejenis akan memberikan dampak jauh lebih besar dibanding tautan dari website acak atau tidak kredibel.
Jika halaman Anda dianggap populer, Google akan lebih sering merayapinya karena diasumsikan bahwa konten tersebut bernilai tinggi bagi pengguna dan berpotensi mengalami perubahan penting dari waktu ke waktu.
Jika ada halaman penting dengan sedikit backlink, bisa jadi halaman tersebut jarang dirayapi.
Solusinya, buat strategi backlink agar lebih banyak wesbite lain menautkan ke halaman-halaman penting Anda. Ini membantu meningkatkan prioritas perayapan dan visibilitas di hasil pencarian.
Staleness
Mesin pencari seperti Google berusaha untuk merayapi konten secara rutin agar bisa mendeteksi perubahan terbaru.
Namun, jika suatu halaman jarang diperbarui atau isinya tetap sama dalam jangka waktu lama, Google bisa saja mengurangi frekuensi perayapan terhadap halaman tersebut.
Sebagai perbandingan, situs berita biasanya dirayapi lebih sering karena mereka menerbitkan konten baru beberapa kali dalam sehari, ini yang disebut dengan crawl demand yang tinggi.
Namun, ini bukan berarti Anda harus memperbarui konten setiap hari hanya demi membuat Google datang lebih sering.
Google sendiri menegaskan bahwa mereka lebih memprioritaskan konten berkualitas tinggi, bukan perubahan yang sering tapi tidak relevan.
2. Crawl Capacity Limit
Crawl capacity limit adalah batas maksimum jumlah permintaan yang dapat dilakukan Googlebot ke situs Anda dalam satu waktu, tanpa membebani performa server.
Tujuannya adalah untuk menghindari gangguan kinerja, seperti situs menjadi lambat atau bahkan tidak dapat diakses karena terlalu banyak permintaan sekaligus dari bot Google.
Hal ini terutama dipengaruhi oleh kesehatan website Anda secara keseluruhan dan batasan perayapan Google sendiri.
Ada dua faktor utama yang memengaruhi crawl capacity limit wesbite Anda:
Crawl Health
Crawl health adalah seberapa cepat dan stabil website Anda merespons permintaan dari Google memiliki pengaruh besar terhadap crawl budget, khususnya dalam hal crawl capacity limit.
Jika situs Anda merespons dengan cepat dan konsisten, Google akan menganggap website Anda sehat dan andal.
- Batas kapasitas perayapan (crawl capacity limit) akan meningkat
- Googlebot akan lebih sering dan lebih cepat merayapi halaman-halaman Anda
- Konten baru atau yang diperbarui akan lebih cepat masuk ke indeks pencarian
Namun, jika website Anda mengalami perlambatan atau waktu muat yang tinggi, Google akan mulai mengurangi kecepatan dan frekuensi perayapan.
Hal ini dilakukan untuk mencegah website mengalami beban server yang berlebihan.
Situasi akan menjadi lebih serius jika:
- Situs Anda mengembalikan error server (seperti error 500, timeout, atau koneksi terputus)
- Server sering tidak stabil atau overload saat menerima request dari Googlebot
Dalam kasus seperti ini, Google akan secara otomatis menurunkan batas kapasitas crawl demi melindungi performa situs.
Imbasnya, halaman-halaman penting Anda bisa terlambat dirayapi atau bahkan terlewatkan dalam proses indeks.
Google’s Crawling Limits
Meskipun Google adalah perusahaan teknologi raksasa, sumber daya yang dimilikinya untuk merayapi seluruh internet tetap terbatas.
Inilah alasan utama mengapa konsep crawl budget diciptakan, untuk membantu Google memprioritaskan halaman mana yang akan dirayapi terlebih dahulu dan seberapa sering.
Dengan miliaran halaman web yang terus bertambah setiap hari, Google harus membagi kapasitas perayapannya secara efisien.
Jadi, tidak semua website bisa dirayapi secara menyeluruh atau setiap hari.
Jika pada suatu waktu sumber daya perayapan Google terbatas, baik karena alasan teknis internal, skala situs, atau beban server global — hal ini bisa berdampak pada crawl capacity limit situs Anda.
Artinya, halaman Anda mungkin akan:
- Dirayapi lebih lambat
- Tidak seluruhnya dijelajahi
- Bahkan terlewatkan untuk sementara waktu
Batasan ini bukan hanya ditentukan oleh kondisi situs Anda saja, tapi juga oleh faktor eksternal dari sisi Google.
Maka dari itu, selain menjaga performa website, penting juga untuk memastikan bahwa struktur website Anda efisien dan tidak membuang-buang crawl budget, misalnya dengan menghindari halaman duplikat, redirect loop, atau halaman yang tidak relevan.
Faktor yang Mempengaruhi Crawl Budget
Googlebot memiliki waktu terbatas untuk merayapi situs Anda. Maka, jangan biarkan crawl budget terbuang sia-sia hanya karena masalah teknis yang sebenarnya bisa Anda kontrol.
Berikut adalah faktor-faktor utama yang bisa menghabiskan crawl budget tanpa manfaat, lengkap dengan solusi terbaik:
1. Faceted Navigation
Faceted navigation adalah fitur filter yang biasanya ditemukan di situs e-commerce, misalnya filter berdasarkan warna, ukuran, merek, atau harga. Fitur ini memang sangat membantu pengguna menemukan produk dengan cepat. Namun, dari sisi SEO dan crawl budget, navigasi ini bisa menjadi bumerang.
Setiap kombinasi filter menghasilkan URL unik yang sebenarnya mengarah ke konten yang mirip atau bahkan sama. Akibatnya, Googlebot akan menghabiskan waktu merayapi ribuan variasi URL yang tidak semuanya penting atau relevan untuk ditampilkan di hasil pencarian. Ini bisa mengurangi frekuensi crawl pada halaman yang benar-benar bernilai SEO.
Solusinya, gunakan atribut rel=canonical, blokir URL yang tidak perlu dengan parameter di robots.txt, atau gunakan parameter handling di Google Search Console.
2. Session Identifiers di URL
Session identifiers atau ID sesi adalah parameter dinamis yang ditambahkan ke URL untuk melacak aktivitas pengguna secara individual, contohnya example.com/page?sessionid=abc123.
Masalahnya, satu halaman bisa muncul dalam berbagai versi hanya karena perbedaan session ID, padahal isinya sama persis. Ini menciptakan banyak URL duplikat yang membingungkan crawler dan memperbesar beban perayapan.
Solusinya, hindari penggunaan session ID dalam URL jika memungkinkan. Gunakan cookie untuk melacak sesi pengguna, dan konfigurasi parameter di GSC untuk membantu Google memahami bahwa parameter tersebut tidak mengubah isi halaman.
3. Konten Duplikat
Konten duplikat terjadi saat dua atau lebih halaman memiliki isi yang identik atau sangat mirip. Misalnya, halaman produk yang sama bisa diakses dari dua kategori berbeda, atau halaman dengan parameter filter yang berbeda tapi menampilkan produk yang sama.
Googlebot tetap akan merayapi semua versi halaman ini, yang tentu menghabiskan crawl budget. Selain itu, konten duplikat dapat menyebabkan kanibalisasi keyword dan menurunkan ranking secara keseluruhan.
Solusinya, gunakan rel=canonical untuk menunjukkan versi utama halaman, atau gunakan redirect 301 dari halaman duplikat ke halaman utama.
4. Konten Berkualitas Rendah & Spammy
Halaman dengan kualitas rendah—misalnya berisi artikel tipis (thin content), penuh keyword stuffing, atau hanya salinan dari situs lain, akan tetap dirayapi oleh Googlebot. Namun halaman ini kemungkinan besar tidak akan diindeks atau diberi ranking yang baik.
Yang lebih merugikan, crawler menghabiskan waktu untuk halaman-halaman yang tidak memberi nilai tambah, sementara halaman penting bisa saja luput dari perayapan.
Solusiny, audit konten Anda secara berkala. Hapus atau gabungkan konten tipis, dan pastikan semua halaman menyajikan informasi orisinal, relevan, dan bermanfaat bagi pengguna.
5. Soft Error Pages
Soft error adalah halaman yang terlihat seperti error (misalnya halaman kosong atau “halaman tidak ditemukan”), tetapi tetap menampilkan status HTTP 200 (OK). Ini membuat Googlebot menganggap halaman tersebut valid dan layak diindeks, padahal sebenarnya tidak.
Akhirnya, crawler mengunjungi halaman ini berulang kali, membuang waktu dan crawl budget yang seharusnya bisa dialokasikan untuk halaman lain yang benar-benar penting.
Solusinya, pastikan halaman error seperti “not found” menggunakan status HTTP 404 atau 410. Gunakan tools seperti GSC dan Screaming Frog untuk mengidentifikasi soft error pages.
6. Situs yang Terkena Hack
Jika situs Anda diretas, peretas bisa menambahkan ratusan bahkan ribuan halaman spam, skrip berbahaya, atau konten tersembunyi yang tidak Anda ketahui.
Ini bukan hanya berbahaya bagi pengunjung, tetapi juga membuat Googlebot menghabiskan banyak waktu merayapi halaman yang tidak berguna dan bahkan bisa merugikan reputasi SEO Anda.
Situs yang terkena hack sering kali kehilangan kepercayaan Google dan bisa mengalami penurunan drastis dalam hasil pencarian.
Solusinya, periksa keamanan situs secara rutin, gunakan plugin keamanan jika menggunakan CMS seperti WordPress, dan segera bersihkan konten mencurigakan. Gunakan fitur keamanan dari GSC untuk mendeteksi aktivitas tidak normal.
7. Infinity Spaces
Infinity spaces adalah bagian website yang memungkinkan crawler mengakses halaman tanpa batas, misalnya kalender arsip harian, “load more” tanpa batas, pagination tak terkendali, atau tautan internal yang terlalu dalam.
Masalahnya, halaman ini sering kali minim konten atau hanya pengulangan konten sebelumnya. Jika tidak dikendalikan, crawler bisa terus merayapi halaman-halaman yang tidak memiliki nilai SEO, menghabiskan budget, dan mengabaikan halaman yang penting.
Solusinya, batasi jumlah tautan per halaman, gunakan atribut nofollow untuk link tidak penting, dan pastikan pagination tidak menyebabkan duplikasi berlebihan. Pertimbangkan struktur arsitektur informasi yang ramping dan efisien.
8. Halaman yang Sering Diperbarui Tanpa Perubahan Signifikan
Jika Anda sering memperbarui halaman hanya dengan perubahan kecil (misalnya edit typo, ubah 1 kata), Google mungkin akan terus merayapinya meskipun kontennya tidak berubah secara berarti.
Solusinya, perbarui halaman secara signifikan sebelum mengindikasikan perubahan pada sitemap (<lastmod>) agar Google hanya merayapi saat ada pembaruan penting.
Cara Mengecek Aktivitas Crawl di Website Anda
Jika Anda ingin mengetahui seberapa sering Google merayapi situs Anda, serta apakah ada masalah yang memengaruhi crawl budget, Anda bisa mengeceknya langsung melalui Google Search Console (GSC).
GSC menyediakan data lengkap tentang aktivitas perayapan Googlebot, termasuk:
- Dan perubahan besar dalam perilaku perayapan dari waktu ke waktu
- Frekuensi perayapan halaman
- Jumlah permintaan (requests) yang dilakukan
- Waktu respons server
- Error atau masalah teknis saat proses crawling
Dengan informasi ini, Anda bisa:
- Mengidentifikasi hambatan teknis yang mungkin membatasi aktivitas perayapan
- Melihat apakah Googlebot mengalami error atau hambatan saat mengakses website Anda
- Mengetahui halaman mana saja yang sering dirayapi dan mana yang tidak tersentuh
Untuk melihat informasi ini, masuk ke properti situs Anda di Google Search Console, lalu klik menu “Settings”.
Di bagian Crawling, Anda akan melihat jumlah permintaan perayapan (crawl requests) yang dilakukan Google dalam 90 hari terakhir.
Selanjutnya, klik tombol Lihat Laporan “Open Report” untuk membuka halaman Crawl Stats yang lebih mendalam.
Over-Time Charts
Di bagian atas halaman Crawl Stats di Google Search Console, Anda akan menemukan grafik perayapan selama 90 hari terakhir.
Grafik ini memberikan gambaran menyeluruh tentang seberapa sering Googlebot mengakses website Anda dan bagaimana performa server Anda saat merespons permintaan tersebut.
Berikut penjelasan dari masing-masing kotak data (widget) utama yang ditampilkan:
- Total Crawl Requests (Total Permintaan Perayapan)
Menunjukkan jumlah total permintaan yang dilakukan oleh Googlebot ke website Anda dalam 90 hari terakhir.
Angka ini mencerminkan frekuensi perayapan dan bisa menjadi indikator apakah Google aktif menjelajahi seluruh halaman di website Anda. - Total Download Size (Total Ukuran Unduhan)
Menginformasikan total data (dalam megabyte atau gigabyte) yang diunduh oleh Googlebot saat merayapi situs Anda. Ini termasuk HTML, gambar, CSS, JavaScript, dan file lainnya. - Average Response Time (Rata-rata Waktu Respons)
Menunjukkan rata-rata waktu yang dibutuhkan server Anda untuk merespons permintaan dari Googlebot, biasanya dalam milidetik (ms).
Semakin cepat waktu respons, semakin baik kualitas pengalaman pengguna dan semakin tinggi kemungkinan crawl budget Anda meningkat.
Status Host
Host Status menunjukkan seberapa mudah Googlebot dapat merayapi situs Anda, berdasarkan ketersediaan dan stabilitas server selama periode perayapan.
Jika server Anda selalu responsif dan stabil, maka Google akan menampilkan status bahwa host Anda dalam kondisi “GOOD”.
Namun, jika situs Anda pernah mengalami kendala teknis, seperti lambat merespons atau terlalu sering error saat Google mencoba merayapi, maka Anda mungkin akan melihat peringatan seperti:
“Host mengalami masalah di masa lalu” (“Host had problems in the past”)
Saat Anda membuka bagian Host Status di laporan Crawl Stats, Anda akan melihat apakah Google mengalami kendala teknis saat mencoba merayapi situs Anda.
Secara khusus, bagian ini akan menunjukkan apakah ada masalah dengan:
- robots.txt tidak bisa diakses
- Masalah DNS (Domain Name System)
- Koneksi server gagal (Server Connectivity Issue
Crawl Requests Breakdown
Bagian ini dalam laporan Crawl Stats di Google Search Console memberikan informasi rinci tentang jenis-jenis permintaan perayapan yang dilakukan oleh Googlebot ke situs Anda.
Data ini dikelompokkan ke dalam beberapa kategori penting berikut:
- Response (“OK (200)” or “Not found (404)”
- URL file type (HTML or image)
- Purpose of the request (“Discovery” for a new page or “Refresh” for an existing page)
- Googlebot type (smartphone or desktop)
Dengan mengklik salah satu item di setiap widget dalam laporan Crawl Stats, Anda bisa melihat detail lebih lanjut — seperti daftar halaman yang menghasilkan status tertentu (misalnya 404 Not Found, 500 Server Error, atau 301 Redirect).
Yang berfungsi untuk mengidentifikasi URL bermasalah yang membuang-buang crawl budget dan memprioritaskan halaman penting agar lebih sering dirayapi oleh Googlebot.
Google Search Console memberikan data langsung dari Google mengenai bagaimana situs Anda dirayapi, termasuk kecepatan respons server, status permintaan, dan kesehatan host.
7 Tips Efektif untuk Optimasi Crawl Budget
Setelah Anda mengetahui di mana letak masalah crawl budget di website Anda, langkah selanjutnya adalah memperbaikinya agar proses perayapan Google menjadi lebih efisien dan terfokus.
Dengan mengoptimalkan crawl budget, Anda memastikan bahwa Googlebot lebih sering mengunjungi halaman-halaman penting, bukan membuang waktu pada URL yang tidak perlu atau bermasalah.
Berikut adalah 7 langkah utama yang bisa Anda lakukan untuk memaksimalkan efisiensi crawl dan mendukung performa SEO Anda:
1. Tingkatkan Kecepatan Situs Anda
Kecepatan website bukan hanya penting untuk kenyamanan pengguna, Google juga memperhitungkannya dalam proses perayapan.
Semakin cepat situs Anda merespons permintaan, semakin besar kemungkinan Google akan merayapi lebih banyak halaman dalam waktu yang lebih singkat.
Artinya, crawl budget Anda digunakan lebih optimal.
Berikut beberapa cara efektif untuk meningkatkan kecepatan situs:
- Optimalkan Gambar Anda: Gunakan tools seperti ImageCompressor untuk mengurangi ukuran file tanpa mengorbankan kualitas. Gambar yang ringan mempercepat waktu muat halaman secara signifikan.
- Minify Kode dan Script Website: Anda bisa menggunakan alat seperti Minifier.org atau plugin WordPress seperti WP Rocket untuk menghapus spasi, komentar, dan karakter tidak penting dari file CSS, JavaScript, dan HTML agar situs lebih ringan.
- Gunakan CDN (Content Delivery Network): CDN membantu menyajikan konten dari server yang paling dekat dengan lokasi pengunjung, sehingga mempercepat proses loading dan mengurangi beban server utama.
- Aktifkan Caching Halaman: Caching memungkinkan halaman website disimpan sementara di browser pengguna atau server, sehingga saat halaman diakses kembali, tidak perlu dimuat ulang dari awal. Plugin seperti LiteSpeed.
2. Gunakan Internal Linking yang Strategis
Struktur internal linking yang cerdas akan memudahkan crawler mesin pencari untuk menemukan, memahami, dan menjelajahi konten Anda. Ini bukan hanya membuat penggunaan crawl budget lebih efisien, tapi juga meningkatkan potensi peringkat halaman Anda di hasil pencarian.
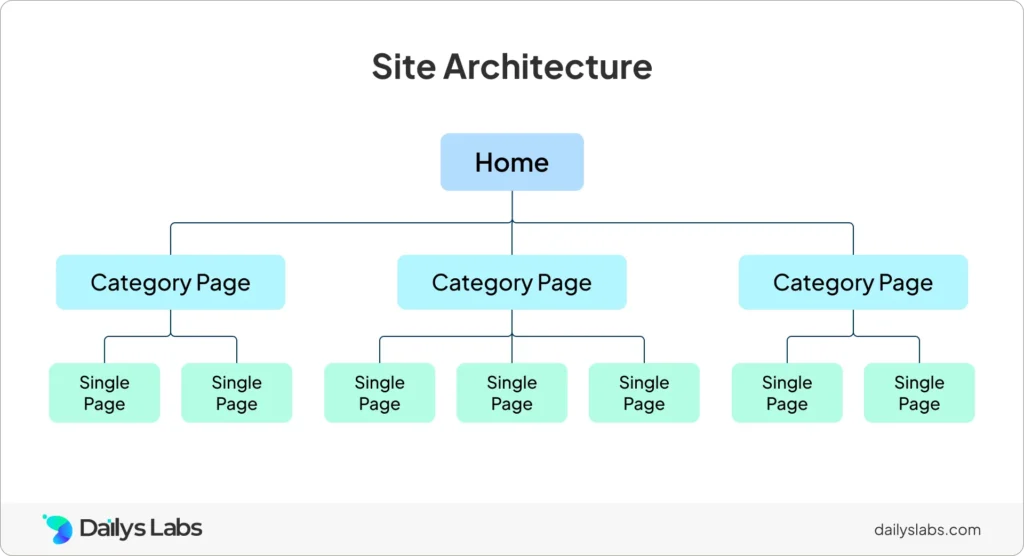
Setiap cabang harus menghubungkan ke halaman-halaman yang relevan dan bernilai tinggi, agar alur navigasi menjadi logis, baik untuk pengguna maupun untuk Googlebot.
Tips Praktis Internal Linking:
- Tambahkan tautan internal ke semua halaman penting agar lebih mudah ditemukan dan dirayapi
- Pastikan tidak ada halaman yang menjadi orphaned page (halaman tanpa tautan internal masuk)
- Gunakan anchor text yang relevan agar Google bisa memahami konteks setiap tautan
Catatan
Google memang bisa menemukan halaman yang tidak ditautkan secara internal, tapi akan jauh lebih cepat dan efisien jika Anda membantunya dengan struktur tautan yang jelas.
Semakin baik Anda mengatur internal link, semakin besar peluang halaman penting Anda untuk lebih sering dirayapi, diindeks, dan tampil di posisi atas hasil pencarian (SERP).
3. Selalu Perbarui Sitemap Anda
Memiliki XML sitemap yang selalu diperbarui adalah salah satu cara paling efektif untuk memberi tahu Google halaman mana yang paling penting di situs Anda.
Saat Anda menambahkan halaman baru, memperbarui sitemap dapat membantu Google menemukan dan merayapi halaman tersebut lebih cepat—meskipun tidak selalu dijamin akan langsung diindeks.
Sitemap Anda biasanya berupa file XML dengan daftar URL seperti ini:
<url>
<loc>https://yourdomain.com/page</loc>
<lastmod>2025-06-17</lastmod>
</url>
Pastikan Anda hanya menyertakan URL yang benar-benar ingin ditampilkan di hasil pencarian dalam sitemap Anda.
Hindari memasukkan halaman duplikat, halaman redirect, atau halaman yang diblokir melalui robots.txt karena hal-hal tersebut hanya akan membuang crawl budget secara sia-sia.
Selain itu, gunakan tag <lastmod> secara bijak untuk memberi sinyal kepada Google kapan terakhir kali sebuah halaman diperbarui.
Terakhir, perbarui sitemap setiap kali ada perubahan besar di website Anda, seperti penambahan artikel baru, penghapusan halaman usang, atau perubahan struktur URL, agar Googlebot selalu mendapatkan peta terbaru dari isi website Anda.
4. Blokir URL yang Tidak Perlu Dirayapi Mesin Pencari
Salah satu cara paling efektif untuk menghemat crawl budget adalah dengan mencegah Googlebot merayapi halaman yang tidak penting atau bersifat privat.
Anda bisa melakukannya dengan mengatur file robots.txt—sebuah file yang memberi tahu mesin pencari halaman mana yang boleh dan tidak boleh dirayapi.
Kenapa harus memblokir halaman tertentu?
Karena tidak semua halaman di website Anda layak dirayapi. Beberapa halaman seperti halaman login admin, halaman filter pencarian, hasil pencarian internal, halaman terima kasih, atau arsip tag yang tak penting, justru bisa menghabiskan crawl budget secara tidak produktif.
User-agent: *
Disallow: /wp-admin/
Disallow: /search/
Disallow: /tag/
Semua baris setelah perintah “Disallow:”, Anda memberi sinyal kepada Googlebot untuk tidak merayapi direktori atau URL tertentu, sehingga Google dapat memfokuskan perayapan pada halaman-halaman yang benar-benar penting untuk SEO.
Tip
Anda bisa pakai tag
noindexuntuk mencegah halaman muncul di hasil pencarian. Tapi Google tetap akan merayapi halaman itu, jadi crawl budget tetap terpakai.Kalau tujuan Anda ingin menghemat crawl budget, sebaiknya gunakan
robots.txtuntuk langsung blokir halaman dari proses perayapan.
5. Hilangkan Konten Duplikat
Duplicate content adalah ketika ada halaman di website Anda yang sangat mirip atau identik satu sama lain.
Masalah ini bisa membuang crawl budget karena bot akan merayapi versi yang hampir sama dari halaman yang sama berulang kali.
Konten duplikat bisa muncul dalam beberapa bentuk, seperti halaman yang benar-benar sama atau hampir identik atau versi berbeda dari halaman karena parameter URL (umum di situs e-commerce)
Untuk mengatasi konten duplikat, Anda bisa:
- Gunakan tag
rel=canonicaluntuk memberi tahu Google halaman mana yang merupakan versi utama - Gabungkan kontennya ke satu halaman utama, lalu gunakan 301 redirect untuk mengarahkan versi duplikat ke halaman utama tersebut
Dengan mengelola konten duplikat secara efektif, Anda bisa memastikan Google fokus merayapi halaman yang benar-benar penting — bukan membuang waktu dan sumber daya pada versi-versi yang mirip.
6. Perbaiki Broken Link
Broken link adalah tautan yang mengarah ke halaman yang sudah tidak aktif, biasanya akan menampilkan kode error 404.
Sebenarnya, halaman yang memang tidak ada boleh mengembalikan status 404. Itu wajar.
Tapi jika situs Anda memiliki banyak tautan yang mengarah ke halaman rusak, itu bisa membuang crawl budget. Karena bot Google tetap akan mencoba merayapi halaman-halaman tersebut, padahal tidak ada konten yang bisa diindeks.
Dan tentu saja, ini juga mengganggu pengalaman pengguna.
Solusinya?
Lakukan audit rutin untuk menemukan tautan rusak, lalu hapus atau perbaiki. Jika halaman lama masih punya nilai, hidupkan kembali atau arahkan ke halaman baru yang relevan dengan 301 redirect, lebih ramah untuk bot, dan jauh lebih baik untuk pengalaman pengguna.
7. Hapus Redirect yang Tidak Perlu
Redirect adalah proses mengarahkan pengguna (dan bot) dari satu URL ke URL lain.
Meskipun berguna dalam beberapa kasus, terlalu banyak redirect bisa memperlambat waktu muat halaman dan menghabiskan crawl budget secara sia-sia.
Masalah akan makin besar jika Anda memiliki redirect chain, yaitu ketika satu URL diarahkan ke URL lain, lalu diarahkan lagi ke URL berikutnya, dan seterusnya.
Googlebot tetap harus mengikuti semua rantai tersebut sebelum sampai ke tujuan akhir, dan itu menghambat efisiensi perayapan.
Solusinya? Audit semua redirect di situs Anda. Hapus redirect yang tidak perlu, dan jika memungkinkan, langsung arahkan URL lama ke tujuan akhirnya (one-step redirect) untuk mempercepat proses crawling dan memberikan pengalaman pengguna yang lebih baik.
Penutup
Crawl budget bukan sekadar istilah teknis, merupaka aset penting yang menentukan seberapa sering dan seberapa banyak halaman Anda dirayapi oleh Google.
Jika Anda tidak mengelolanya dengan baik, halaman-halaman berkualitas tinggi bisa terabaikan, sementara bot malah sibuk merayapi URL tak penting, duplikat, atau error.
Mulailah dengan mengidentifikasi pemborosan crawl budget seperti halaman duplikat, redirect berantai, dan konten berkualitas rendah.
Optimalkan sitemap, internal linking, serta robots.txt Anda untuk mengarahkan Googlebot ke halaman-halaman yang paling bernilai. Dan jangan lupa, kecepatan situs serta struktur URL yang bersih juga memainkan peran besar dalam efisiensi perayapan.
Dengan menerapkan tips-tips di atas, Anda tidak hanya menjaga crawl budget tetap efisien, tetapi juga meningkatkan peluang halaman penting Anda untuk lebih cepat terindeks dan muncul di hasil pencarian.
Jika Anda merasa artikel ini bermanfaat untuk memahami dan mengoptimalkan crawl budget website, jangan lupa untuk membagikannya ke rekan atau komunitas Anda.
Kami juga sangat terbuka untuk diskusi — silakan tinggalkan komentar jika Anda punya pertanyaan atau insight tambahan. Dan pastikan Anda berlangganan blog kami agar tidak ketinggalan update konten SEO terbaru dan praktis lainnya.
Butuh bantuan teknis untuk mengoptimalkan crawl budget, mempercepat website, atau menyusun struktur internal link yang efisien? Dailys Labs siap membantu Anda dengan layanan Techncial SEO.
Hubungi kami sekarang untuk konsultasi gratis dan mulailah langkah strategis menuju peringkat teratas di hasil pencarian.
